

koly
koly
本篇为译稿,原文出处:support.office.com
一个设计良好的数据库能够保证数据的时效性及准确性。当需要同数据库交互的时候,良好的设计才能保证任务的完成,而投资时间去学习好的设计原则是有意义的。学完之后,你就能够设计出既满足需求又适应变化的数据库。
本文对数据库的设计提供了一些指导。你会学到如何确定你需要哪些信息,如何将信息分解为合适的数据库表和其中的列,以及表与表之间应当如何关联。在你创建自己第一个数据库之前,你应该读读本文。
目录:
Access 2010使用表(table)的形式来组织信息:一排排的行和列就像会计使用的纸板或电子表格。一个简单的数据库可能只有一个表。而大部分数据库包含的表往往不止一个。比如说,你可能需要一个表来存储产品信息,另一个表来存储订单信息,而第三个表来存储客户信息。
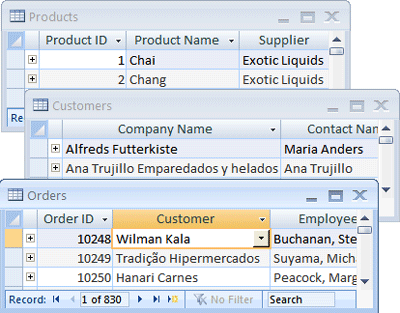
每一行称为一个记录(record),每一列称为一个属性(field)。记录是一种有意义的一致的信息,它记载了某个事物的某些方面。列是信息中的一部分——这部分出现在每个记录中。举个例子,在产品表中,每一行表示一个产品的信息。每一列表示产品的某个信息,比如产品的名字或者价格。
在数据库设计中,有一些指导性原则。第一,重复信息(又叫冗余信息)是不好的。因为它既浪费空间又增加了错误和不一致的可能。第二,信息的正确性和完整性是非常重要的。如果数据库包含了错误信息,那么任何由此产生的报告都是错的。当然,基于这些报告所做的决定也是错的。
因此,一个好的数据库设计应该:
数据库的设计流程包含以下几步:
将数据库的目的、你希望怎么使用以及谁去使用等信息写在纸上,是一个好的方法。举个例子,对一个主要应用于小作坊生意的数据库,你可能会写下“客户数据库保存一系列的客户信息,以便产生邮件和报表”。如果数据库比较复杂或者被多个人使用——正像在大公司里的情况——此时目的可能就需要写几段,并且应当包含什么时候,谁将怎么使用数据库。这样做的目的是方便在数据库设计的任何阶段都可以有一个声明可以参考。当你在做决定的时候,这个声明能帮你把注意力集中在目标上。
寻找并组织所需要的信息,从你当前知道的信息开始。比如说,你可能在一个分类账上记录了订单信息,抑或将客户信息记录在了文件柜中的纸质表上。将这些东西收集起来,并且列出每一项(比如,表中的每一个表格)。如果当前你没有这些表格,试想你需要设计一张表格来记录客户信息。你需要将什么样的信息放在表上?你将创建什么样的表格?确定并列出这些东西。再比如,假设当前你将客户列表记录在索引卡上。每张卡上可能记录了客户名字,地址,城市,州,邮编及电话号码。每一项都可能映射为表中的一列。
在你准备这个列表的时候,不要想着一开始就得到一个完美的结果。相反,想到什么就列出什么。如果别人也要使用这个数据库,问问他们的意见。晚些时候,你是可以修改这个列表的。
下一步,考虑你想从数据库中产生的报表或邮件。比如,你希望可以根据数据库中的信息创建某个区域的产品销售报表,或者显示存货水平的存货信息表。你也可能想要创建发给客户的信件,以便告知客户一些销售活动或者提供一些折扣。在脑子里设计一下报表,想象可能是什么样子。你希望报表上有什么信息?列出来。同样地,你也可以想想信件或者其他的报告。

想想你希望创建的报表和邮件,这会帮助你发现那些你需要的信息。举个例子,假设客户能够选择周期性的关于更新的电子邮件,而且你想打印出一个列表,上面记录了选择了接收邮件的人。为了记录这个信息,你在customer表上加了一列“send e-mail”。对于每个客户,你可以设置那列为“Yes”或者“No”。
为报告或者列表建立一个原型并考虑创建它们需要的信息往往很有帮助。比如,当你考虑一封信时,一些东西就会自然地出现。如果你希望有一个合适的称呼——先生,女士或者小姐,你可能需要加上一个称呼项。还有,你可能希望以“Dear Mr. Smith”开头,而不是“Dear. Mr. Sylvester Smith”。这表示你要将名和姓分开存储。
你需要记住的一点是信息应该在有用的前提下被分解得最小。在名字那个例子中,为了让姓可以单独出现,名字被分解成了名和姓。为了可以按照性来排序,客户的姓就需要单独成为一列。通常,当你想要对信息中的某一项进行排序,搜索,计算或报道的时候,那一项就应该成为单独的一列。
想想数据库可能需要回答的问题。比如,上个月某个产品卖了多少?最好的客户住在什么地方?卖的最好的产品的供应商是谁?这些问题可以帮你想到一些额外需要的信息项。
收集完信息之后,就可以进行下一步了。
要想将信息分解为表,就要选择重要的或主要的实体(entity)或主体(subject)。比如,在找出一个销售系统的信息后,最初的设计可能是这样的:

上图中,产品(products)、供应商(suppliers)、客户(customers)和订单(orders)就是实体。据此,我们可以得到对应的四个表:products, suppliers, customers, orders。虽然这并不完整,但至少是一个好的开始。你可以持续修正这个列表直到你满意为止。
当你刚开始回看这个列表的时候,你可能想要把所有的信息放到同一个表里,而不是建立单独的四个表。这不是一个好主意,接下来你将知道为什么。考虑下面的表:
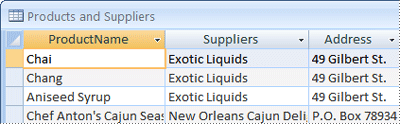
这时,每一行同时表示产品及其供应商的信息。由于同一个供应商可以供应多个产品,供应商的名字和地址信息必须被重复许多次。这是对空间的浪费。一个更好地方式是:用一个单独的供应商表来记录供应商信息,并将其链接到产品表中。
在你需要修改供应商信息的时候,你会发现这个设计的另一个问题。比如,假设你需要更改供应商的地址。由于该供应商的信息出现在了许多地方,你很有可能只更改了一些,而遗漏了另一些。如果供应商的信息是存储在同一个地方的,这种问题将不会发生。
在设计数据库的时候,尽量将一种信息只记录在一个地方。如果你发现同样地信息在不同的地方出现,比如刚才的供应商地址,就把这些信息放到单独的表中。
最后,假如只有一个产品是由供应商Coho Winery提供。而你想要删除这个产品,但同时保留供应商的名字和地址信息。如果所有的信息都在同一行,你怎么才能在删除产品的同时保留供应商信息呢?这做不到。因为每一条记录同时包含了产品和供应商的信息,删除一个就必须同时删除另一个。要将他们分开,你就需要将表拆分为两个:一个记录产品信息的表,另一个记录供应商信息的表。删除一个产品,应当只删除所有产品信息,而不是还要删除供应商信息。
一旦你确定了可以用表来实现的实体,表中的列就应该只表示关于该实体的信息。举个例子,产品表应该只存储关于产品的信息。而供应商地址是关于供应商的信息,跟产品没有关系,所以它应当属于供应商表。
确定表中的列,需要确定关于该实体的哪些信息应当被记录下来。比如,对于客户表(customer),名字,地址,邮编,是否发了邮件,称呼和邮箱地址是比较好的可称为列的选择。表中的每一条记录包含了同样的列。所以每一条记录都会有名字,地址,邮编,是否发了邮件,称呼和邮箱地址。比如,地址列记录了客户地址。每一条记录包含了一个客户的数据,而地址列则包含了该客户的地址信息。
先拟定一个表的可能列,然后再进行修正。比如,首先将客户名字分成单独的两列:名(first name)和姓(last name)。这样就快要根据这两列进行排序,查找和索引。同样地,地址也包含五个单独的部分:地址,城市,州,邮编和国家/地区,将这些信息分开存放也是有用的。当你需要进行一次搜索并按州来排序或过滤的适合,你就需要州是一个单独的列。
你也应当考虑数据存储的信息是针对国内的还是同样可以针对国外的。比如,如果想要存储国际地址,使用地区(region)列就比使用州(state)好,因为地区列既可以表示国外的地区也可以表示国内的州。同样地,使用Postal Code比Zip Code好。
下面有一些小技巧:

当你确定了表中的每一列后,你就快要为每张表选择主键了。
每一张表都应该有一列或者几列来唯一标识一行。一般使用一些唯一的序号,比如员工工号或者一个连续数。用数据库术语来讲的话,这就叫做主键(primary key)。Access使用主键来讲表中的数据关联起来并提供给你。
如果表中已经有一个唯一的标示符(identifier)了,比如商品编号,你可以直接使用它作为主键。但你得确认这列中的数值一直都不一样。主键不能有重复的值。比如,人名不能作为主键,因为名字不是唯一的。同一张表里面很有可能有相同的名字。
主键必须有值。如果某些情况下,列的值可能为空或者没有值,那该列就不能成为主键。
主键的值不应该变化。在有多个表的数据库里,一张表的主键可能会在别的表里被引用。如果主键值变化了,引用的每一处都应当相应变化。使用一个值不变的主键,可以减少其在别的表中没有及时同步的可能。
很多时候,一个唯一的数字会被用作主键。举个例子,你可以给每一个订单设置一个唯一的订单号。订单号的唯一目的就是标识一个订单。一旦设置了,再不会改变。
如果你没有找到合适的一列或者多列来作为主键,考虑使用一个自增长的数字。当你使用自增长的数字的时候,Access会自动给你一个值。这样一个标识符是没有现实意义的。它没有代表现实中的任何东西。这样的列用来做主键是合适的,因为他们不会变化。一个主键如果与现实有关,那就容易变化,因为现实中的信息可能变化。比如电话号码或者客户名。
某些情况下,你可能想要同时使用两个或多个列来作为主键。比如,一个保存了订单项信息的订单详情表可能使用订单号和商品号来作为主键。当主键包含了两个或两个以上的列时,我们称之为复合主键(composite key)。
对于商品买卖数据库,你可以使用自增列作为每张表的主键:Products表中的ProductID,Orders表中的OrderID,客户表中的CustomerID,以及供应商表中的SupplierID。

在你将信息组织为表之后,你需要一种方式再将信息联合起来。比如下面的表包含了几张表中的信息:
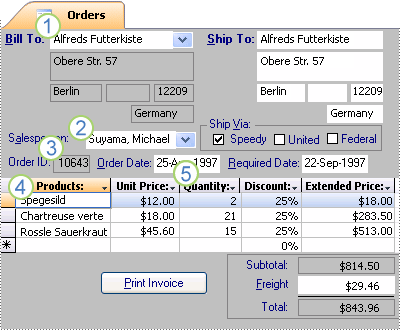
Access是一个关系型数据库管理系统。在关系型数据库中,信息被组织成单独的内聚的表。然后使用表关系将信息根据需要联合起来。
想想这个例子:商品订单数据库中的供应商和商品表。一个供应商可以提供任意数量的商品。对于供应商表中任一数据,可以对应产品表中的多个商品。因此,供应商表和商品表的关系是一对多的关系。
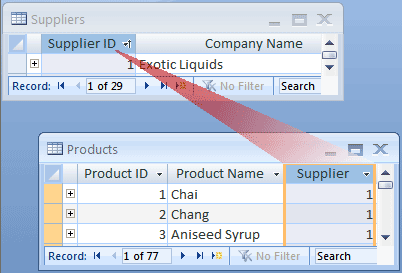
在数据库设计中表示一对多关系时,首先将“一”那一方的主键作为一列加到“多”那一方的表中。这里,你需要将Supplier ID列加到Products表中。这样,Access就能使用Supplier ID定位每个商品的供应商。
此时,商品表中德Supplier ID列就叫做外键(foreign key)。外键是另一张表的主键。Products表中的Suppier ID就是一个外键,因为它是Suppliers表中的主键。

要想将表联合起来,需要首先简历主键和外键的对应。如果你不确定那些表应该共用同样的列,确定一对多关系可以帮你拿主意。
想想Products表和Orders表。
一个订单可以包含多个商品。同时,一个商品可能出现在多个订单中。因此,对于Orders表中的每条记录,可能在Orders表中有多个对应。而对于Products表中的一条记录,也可能在Orders表中有多个对应。这种关系被称为“多对多”,因为对任意一个商品,都可能对应多个订单;对任意一个订单都可能包含多个商品。
Orders表和Products表是一种多对多关系。这带来了一个问题。假设你在Orders表中加上了一列Product ID来表示Orders表和Products表的关系。由于每个订单有多个商品,所以每个订单可能需要不止一行来进行记录。而在这些记录中,你不得不重复一些订单信息,这是种低效的设计,而且也有可能导致数据的不准确。如果你在Products表中添加一列Order ID,你也会遇到同样的问题。怎么解决呢?
答案是建立第三张表,通常称为联结表(junction table)。这张表将多对多关系分解成为了一对多关系。新建的表存储的是两张表的主键。如此,第三张表中出现的记录代表了两张表的多对多关系。
Order Detail表中的每条记录代表了订单中的一项。该表的主键包含两列——来自Orders表和Products表的主键。仅仅使用Order ID是无法成为主键的,一个订单可以有多项。同样的Order ID可能多次出现,因此该列的值并不唯一。对于单独使用Product ID,也是一样。但如果同时使用,则可以。
在商品买卖数据库中,Orders表和Products表并不是直接连接起来的。它们通过Order Details表来关联起来。Orders表和Products表的多对多关系是由两个一对多关系来表示的:
通过Order Details表,你可以知道任一个订单中的所有商品信息。你也可以找到包含任一个商品的所有订单。
在加入Order Details表之后,设计变为了:
另外一种关系是一对一关系。比如,假设你需要记录一些很少用到或者仅针对部分商品的特殊信息。由于这些信息不会经常用到,而却将这些信息存储在商品表中会导致部分商品的列为空,所以你将这些信息放到了一张单独的补充表中。就像Products表一样,你选择了ProductID作为主键。对于Product表中的任一行,在补充表中都有一个对应的记录。当你发现了这种关系,就意味着两张表必须使用同一个列。
当你发现你的数据库中存在这样的一对一关系时,想想你是否可以将两张表的信息放到一张表中。如果你不想那么做,那么可能是因为那会导致空列出现。下面列出了你可以在设计中可能表示一对一关系的方式:
确定表与表直接的关系有助于帮你确定你的设计是对的。当一对一或者一对多关系存在时,相关的表需要使用同一列或者同样几列。当多对多关系存在时,你需要第三张表来表示那种关系。
当你有了这些表、列、及表与表的关系之后,你应该创建表并且填充一些数据,然后进行一些操作,比如创建查询,添加新纪录等等。这样有助于发现潜在的问题。举个例子,你可能在设计的时候忘记添加了一列,或者你需要将一张表拆为两张表以消除重复。
看看通过你的设计你能不能得到你想要的。创建一些粗糙大概的表单或报表来看看你是不是可以看到想要的数据。寻找不必要的重复数据,当你找到的时候,调整设计来去除它。
当你探索你最初的设计时,你很有可能会找到一些提升之处。这里有一些地方你可以试着检查:
假设商品销售数据库中的每个商品都有一个类别,比如饮料、调料或者海鲜。Products表有一列来表示每个商品的具体类别。
假设在检查和修订你的数据库之后,你决定使用Category Description来存储类别信息。如果你在Products表中加上一列Category Description,你就必须在某个类别的多个商品记录里重复类别信息,这显然不是一个好的办法。
更好的办法是将类别作为数据库需要记录的一个新主题,建立对应的表和主键。然后你就可以将Categories表中的主键加到Products表里作为主键。
Categories和Products表是一种一对多关系:一种类别可以有多个商品,但是一个商品仅属于一种类别。
当你审查你的表结构时,记得看看有没有重复。比如,有一张包含以下列的表:
这张表里,每个商品包含了一系列的列,这些列与别的列的不同仅仅体现在最后的数字上。当你发现有一些列是这样的适合,就表示你需要重新审视你的设计了。
这样的设计有几个缺点。首先,它限制了商品的数量。一旦你超过了限制,你就必须加上额外的几组列,这不是一个简单的管理任务。
其次对于提供的商品少于最大数的供应商,某些列会是空的,这就浪费了空间。最严重的缺点是,这样的设计会让很多任务难以完成,比如根据product ID或者name进行排序和索引。
任何时候,当你看到重复的列时,考虑将表分为两张。上例中,最好将表分成两张表,一张存储供应商信息,一张存储商品信息,通过供应商序号链接起来。
下一步,你可以对你的设计运用归一化原则。这些原则可以帮助你检查表的结构是否是合理的。这个过程称为归一化数据库,或者就是归一化。
当你找到了所有的信息项,并且有了一个基础的表设计后,归一化才能发挥最大作用。它会帮你确定你是否将信息合理地分解成了表。归一化并不能保证你一开始的数据项是正确的。
归一化是具有层次性的,每一步你都需要保证你的设计满足了某些“范式”。被广泛采用的范式有五条——第一范式到第五范式。本文讲解了前三条,因为对大部分数据库设计,满足前三条就足够了。
第一范式表明,表中任意行和列的交接处,只存在一个值,并不存在多个值。比如,你不可能在一个叫做价格的列里同时存放多个价格。如果你将行和列的交接处想象为一个单元,那么每个单元只能存放一个值。
第二范式要求没有作为键的列必须完全依赖于主键,而并非只依赖于主键的部分。这个原则应用于使用多列作为主键的情况。比如,加入你有张表包括了下面几列,Order ID和Product ID两者联合作为主键:
这个设计违反了第二范式,因为Product Name仅依赖于Product ID, 并非Order ID,所以它没有完全依赖于主键。你应该将Product Name移除,它属于另一张表(Products)。
第三范式要求不仅没有作为键的列需要完全依赖主键,还要他们彼此独立。
也就是说,没有作为键的列必须只依赖于主键。比如,你有一张表包含了一下几列:
假设Discount依赖于SRP(suggested retail price)。这张表违反了第三范式因为一个非键列,Discount,依赖于另一个非键列,SRP。列间依赖你在改变任意非键列的同时不会对其他非键列造成影响。上例中,如果你改变了SRP列的值,Discount列的值就会受到影响,这就违反了第三范式。这里,Discount应该被移到另一张以SRP为键的表中。
{kind=link}
{kind=link}